Si vous débutez dans l’automatisation de vos tâches professionnelles et que vous ne savez pas par où commencer, l’outil Make offre une plateforme puissante pour simplifier les processus répétitifs. L’objectif est de vous inspirer en détaillant cinq scénarios d’automatisation faciles à mettre en place, que vous pourrez adapter précisément à vos besoins.
Vous pouvez retrouver ma vidéo qui explique chacun de ces 5 automatisations :
1. Automatisation de la création de factures à partir d’emails
La gestion manuelle des factures reçues par email est souvent une tâche chronophage, surtout lorsque ces informations arrivent de manière récurrente de plusieurs clients ou partenaires. Ce scénario vise à transformer un email de notification de paiement en une facture générée automatiquement dans votre logiciel de facturation.
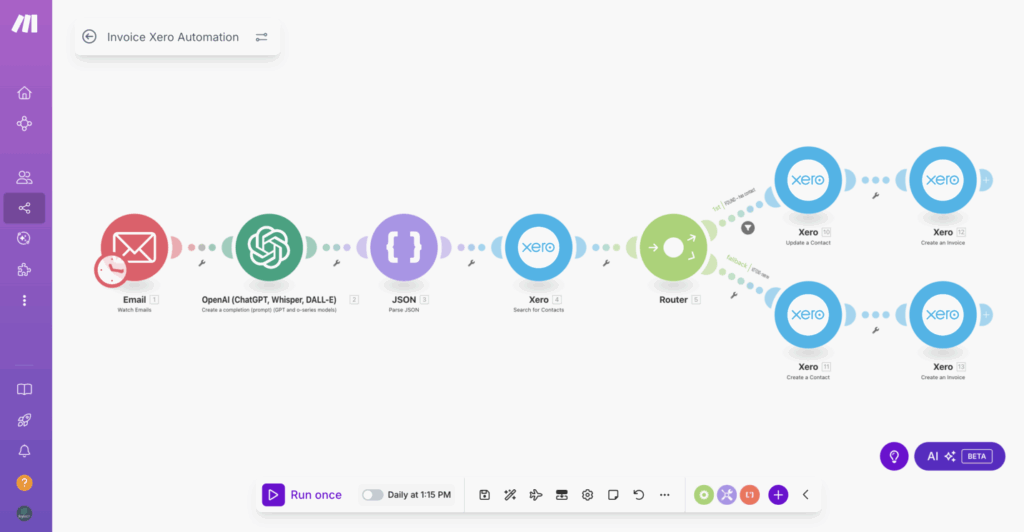
Le déclencheur et la normalisation des données
Le scénario commence par la réception d’un email. Il est possible de filtrer cet email en fonction de l’expéditeur ou du sujet (s’il contient les termes « facture » ou « paiement »). L’étape cruciale suivante est de normaliser les données extraites de cet email.
Pour cela, on demande à ChatGPT d’analyser l’email reçu et de convertir les données pertinentes en format JSON. Cette conversion est essentielle, car elle permet d’établir une règle de formatage uniforme, notamment pour les montants (dollars, euros, etc.), garantissant que votre logiciel de facturation reçoive des informations cohérentes. Le prompt de ChatGPT peut être configuré pour extraire des informations détaillées telles que le nom de l’entreprise, le contact, l’adresse, et les devises.
Une astuce avancée consiste à configurer directement le module de l’outil d’IA (comme ChatGPT) pour qu’il renvoie la réponse au format « Objet JSON », ce qui permet d’éviter l’étape de conversion manuelle subséquente.
Gestion des contacts et création de la facture
Une fois les données structurées en JSON, le scénario utilise un module pour rechercher si le contact existe déjà dans votre logiciel de facturation (l’exemple utilise Qonto/Qzero, mais Make est compatible avec des centaines de modules). Le filtre de recherche est généralement basé sur le nom du contact.
Le scénario se divise alors en deux cas de figure :
- Si le contact existe : Le système met simplement à jour les informations du contact existant (en utilisant son ID) et procède à la création de la facture en utilisant les données JSON structurées (contact ID, description, quantité, prix, codes de facturation, taxes, etc.).
- Si le contact n’existe pas : Le système crée un nouveau contact avec les informations extraites de l’email, puis génère la facture correspondante.
2. Le srapping de données d’entreprises via Google Map
Cette automatisation permet de collecter massivement des informations sur des entreprises ciblées, par exemple, pour dresser une liste d’agences web dans les principales villes de France, évitant ainsi les recherches manuelles chronophages.
Préparation et déclenchement
Le point de départ du scénario est une base de données, comme AirTable (ou Google Sheet), qui sert à lister les critères de recherche. Dans cette base, il faut identifier :
- Les termes à rechercher (ex. : « agences web »).
- Les villes ciblées (filtrées initialement par des critères comme la population).
- Le nombre maximum de recherches à effectuer par ville.
- Une colonne Action qui sert de déclencheur.
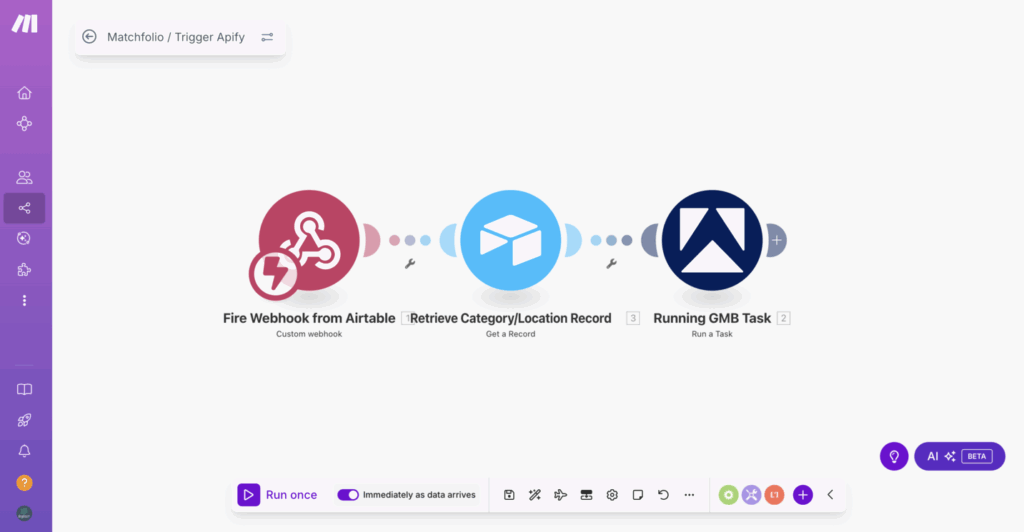
Le déclencheur est mis en place directement dans AirTable : lorsqu’un bouton est activé ou une condition est remplie, un script est exécuté qui lance une Webhook (URL). Cette URL est ensuite collée dans le scénario Make pour initier l’automatisation.
Scraping avec Apidy
Make va ensuite récupérer les informations de la ligne AirTable concernée. Le scraping est réalisé à l’aide d’un outil externe appelé Apify, une plateforme qui propose des applications pour scraper des données issues de Google Map, Instagram, Facebook, etc..
L’outil utilise le Google Map Scraper configuré pour intégrer le terme de recherche, la ville et le nombre de recherches souhaitées. La connexion entre Make et Apify se fait via la copie d’un code JSON. Ce code est ajusté dans Make pour remplacer les exemples statiques par des variables dynamiques issues d’AirTable, comme la localisation et le nombre de recherches.
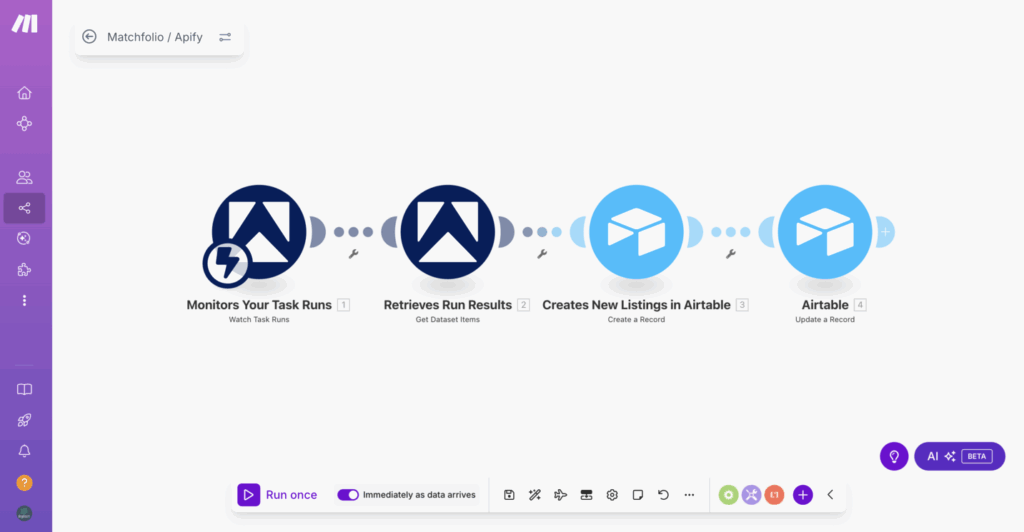
Une fois le scrapping lancé, Apify recueille des informations comme les adresses, numéros de téléphone, avis, horaires, noms de l’agence, site internet et page LinkedIn. Ces données sont ensuite ajoutées et mises à jour automatiquement dans une nouvelle table AirTable (appelée ici « prospection »). Ce processus permet de scraper des dizaines, voire des centaines de données d’entreprise en quelques minutes.
3. Automatisation de la prospection par email
Suite à la collecte de données, ce scénario utilise les informations d’AirTable pour automatiser l’envoi d’emails personnalisés.
Le scénario de prospection démarre par le module AirTable « Search records ». Il est nécessaire d’avoir au préalable ajouté une colonne de statut dans la base de prospection AirTable, avec des options comme « à contacter », « déjà contacté » et « à relancer ».
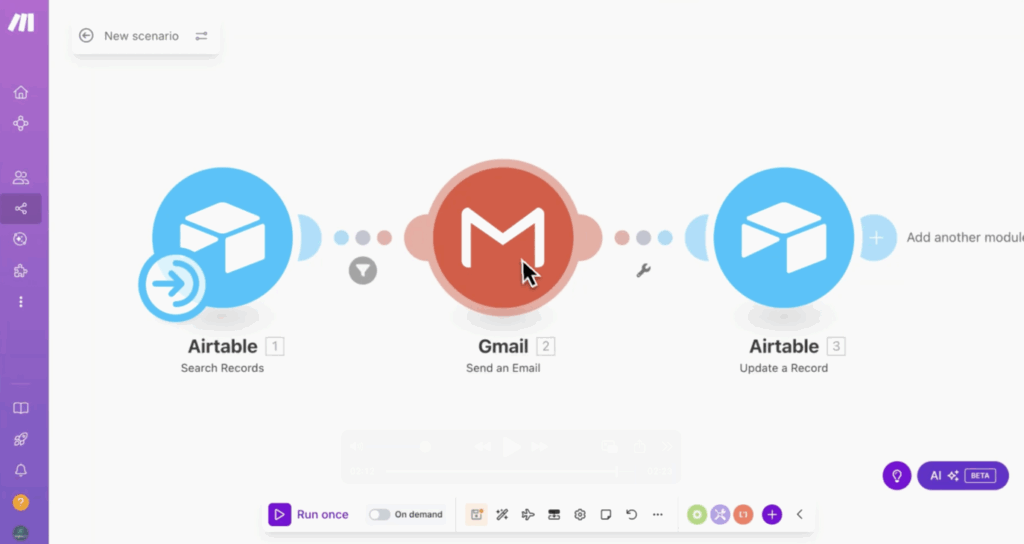
L’envoi des emails est géré soit par un module global, soit spécifiquement par un module comme Gmail « Send email ». Le sujet et le corps de l’email sont personnalisés en utilisant les données récoltées (par exemple, « Bonjour la team [Nom de l’agence] », avec l’URL de leur site). Bien que l’exemple montre un cas simple, l’objectif est de rendre l’email de prospection le plus persuasif possible et d’y ajouter, si nécessaire, des pièces jointes comme un portfolio.
Un filtre est appliqué pour que l’envoi ne se déclenche que si le statut du contact est défini sur « à contacter ». Une fois l’email envoyé, un module « Update record » met automatiquement à jour le statut du contact à « déjà contacté », permettant d’éviter les doublons et d’organiser les futures relances.
4. Création et publication automatisée d’articles d’actualité
Ce scénario permet d’automatiser la veille d’actualité et la rédaction d’articles basés sur ces nouvelles, minimisant ainsi le temps passé à créer du contenu. Il se décompose en deux phases : la veille et la génération.
Phase 1 : Veille et centralisation
L’étape de veille utilise un outil de gestion de flux RSS comme Inoreader. On y configure les news feeds (flux d’actualité) et les sources souhaitées. Make récupère ensuite les informations (titre, éditeur, date, URL de l’actualité) et les alimente dans un fichier AirTable.

Phase 2 : Génération de l’article
La rédaction est lancée à partir d’un Webhook, déclenché par une automatisation dans AirTable. Cette automatisation est liée à un trigger, par exemple, le fait de cocher la colonne « rédiger un article ».
- Recherche via Perplexity : Le module Perplexity est utilisé pour effectuer des recherches supplémentaires sur le sujet issu de l’AirTable. L’objectif est d’utiliser non pas une seule source, mais de demander à Perplexity de chercher trois sources additionnelles sur le même sujet, enrichissant ainsi le contenu de base.
- Rédaction via Claude : L’outil Claude est préféré à ChatGPT pour la rédaction, en raison de sa performance supérieure en matière de style. Claude se base à la fois sur la source et le titre initial, et sur les informations approfondies fournies par l’API de Perplexity. Il est crucial de fournir des instructions précises concernant la structure et le style souhaité pour obtenir un résultat optimal.
- Préparation à la publication : Pour faciliter la publication sur WordPress, deux modules de Text Parser sont utilisés. Ils servent à scinder la sortie de Claude, séparant distinctement le titre et le contenu de l’article, car la réponse initiale mélangerait les deux.
- Publication sur WordPress : Le scénario se connecte à WordPress et utilise les données séparées pour publier l’article en brouillon. L’article généré est correctement structuré et prêt à être finalisé.

Il est également possible d’ajouter une étape facultative utilisant Google Gemini pour générer une image d’illustration à partir du sujet de l’article et de l’uploader directement sur WordPress.
5. Publication sur les réseaux sociaux
Pour maximiser l’impact de votre contenu, ce scénario automatise la publication de vos articles de blog sur plusieurs réseaux sociaux simultanément. Le point de départ est un article fraîchement publié sur WordPress.
Le scénario se divise en plusieurs branches correspondant aux réseaux sociaux ciblés (LinkedIn, Facebook, Instagram), car chaque plateforme requiert un format et une longueur de texte différente.
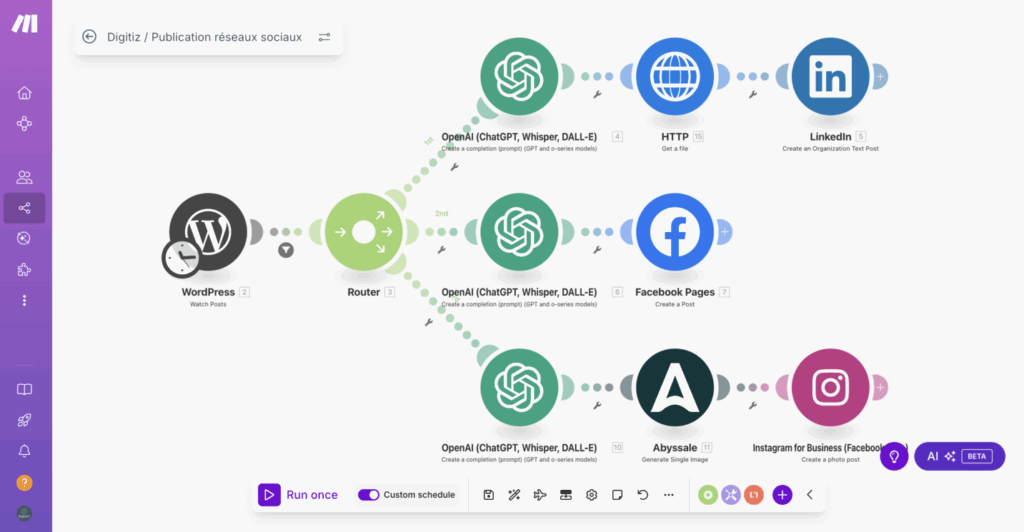
Adaptation du contenu via IA
Pour chaque réseau social, le module Open AI est utilisé pour rédiger une description de l’article adaptée aux contraintes spécifiques de la plateforme (par exemple, un style plus professionnel pour LinkedIn). Les instructions fournies à Open AI incluent le titre, l’extrait de l’article, et le lien.
Gestion des images spécifiques aux plateformes
- LinkedIn : L’article est publié sur la page LinkedIn (et non le profil personnel). Pour inclure l’image d’illustration de l’article, il est nécessaire d’utiliser le lien et d’ajouter l’option thumbnail en cochant HTTP Get File pour récupérer le fichier généré précédemment.
- Facebook : L’image est souvent générée automatiquement par Facebook à partir du lien de l’article, simplifiant cette étape.
- Instagram : Instagram exige un format carré. Dans ce cas, un outil appelé Abyssale est intégré au scénario. Abyssal fonctionne comme un éditeur (similaire à Photoshop), permettant de créer un template standardisé. À partir du titre et de l’illustration de l’article WordPress, Abyssal génère un visuel adapté au format carré, incluant un appel à l’action pour lire l’article complet.
L’objectif final de cette automatisation est de réduire au minimum le temps passé à relayer vos articles, assurant une présence cohérente et rapide sur toutes vos plateformes. Par ailleurs, j’avais fais un tutoriel plus détaillé sur cette automatisation si jamais ça vous intéresse.