Stable Diffusion, connu pour son art génératif, peut maintenant animer des images, a annoncé le développeur Stability AI. La société a lancé un nouveau produit appelé Stable Video Diffusion, permettant aux utilisateurs de créer des vidéos à partir d’une seule image. « Ce modèle de vidéo générative IA de pointe représente une étape importante dans notre parcours vers la création de modèles pour chacun de tout type, » a écrit la société.
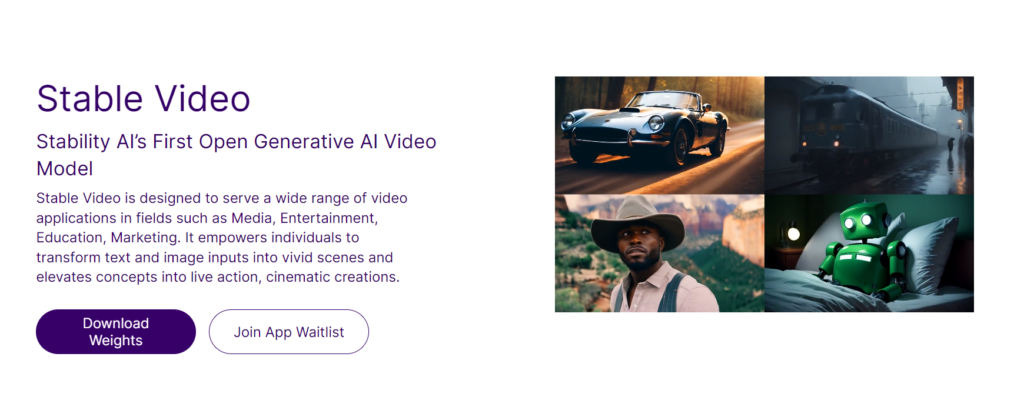
Le nouvel outil a été lancé sous la forme de deux modèles image-vers-vidéo, chacun capable de générer des vidéos de 14 à 25 images d’une durée entre 3 et 30 images par seconde à une résolution de 576 × 1024. Il est capable de synthèse multi-vues à partir d’une seule image avec un ajustement fin sur des ensembles de données multi-vues. « Au moment de la sortie dans leur forme fondamentale, à travers une évaluation externe, nous avons trouvé que ces modèles surpassent les modèles fermés leaders dans les études de préférence des utilisateurs, » a déclaré la société, en les comparant aux plateformes text-to-video Runway et Pika Labs.
Qu’est-ce que Stable Video Diffusion?
Stability AI a annoncé un nouveau modèle d’IA appelé Stable Video Diffusion. Ce modèle génère des vidéos en animant des images existantes et est l’un des rares modèles de génération de vidéos disponibles en open source. Cependant, le modèle est actuellement en « avant-première de recherche » et les utilisateurs doivent accepter certaines conditions d’utilisation avant de pouvoir l’utiliser. Ces conditions d’utilisation définissent les applications prévues du modèle, telles que les outils éducatifs ou créatifs, la conception et d’autres processus artistiques. Elles spécifient également les utilisations non prévues, telles que les représentations factuelles ou vraies de personnes ou d’événements.
Stable Video Diffusion se présente sous deux modèles – SVD et SVD-XT. SVD transforme des images fixes en vidéos de 576×1024 en 14 images, tandis que SVD-XT monte les images à 24. Les deux modèles peuvent générer des vidéos entre trois et 30 images par seconde. Les modèles ont été entraînés sur un ensemble de données de millions de vidéos, puis affinés sur un ensemble plus petit de centaines de milliers à environ un million de clips. La source des données d’entraînement n’est pas immédiatement claire.
Cependant, le modèle a certaines limitations. Il ne peut pas générer de vidéos sans mouvement ou de panoramiques lents de la caméra, être contrôlé par texte, rendre le texte lisible, ou générer de manière cohérente des visages et des personnes. Malgré ces limitations, le modèle peut générer des clips de haute qualité de quatre secondes et peut être adapté à des cas d’utilisation comme la génération de vues à 360 degrés d’objets.
Toutefois, bien qu’il soit encore tôt, Stability note que les modèles sont assez extensibles et peuvent être adaptés à des cas d’utilisation comme la génération de vues à 360 degrés d’objets.
Alors, en quoi pourrait évoluer Stable Video Diffusion ? Eh bien, Stability dit qu’elle prévoit « une variété » de modèles qui « s’appuient sur et étendent » SVD et SVD-XT, ainsi qu’un outil « text-to-video » qui apportera la saisie de texte aux modèles sur le web. L’objectif ultime semble être la commercialisation – Stability note à juste titre que Stable Video Diffusion a des applications potentielles dans « la publicité, l’éducation, le divertissement et au-delà. »
La pression des nouveaux investisseurs
Certes, Stability est déterminée à réussir alors que la pression monte de la part des investisseurs dans cette startup.
En avril, Semafor rapportait que Stability AI brûlait du cash, poussant à une chasse aux cadres pour stimuler les ventes. Selon Forbes, l’entreprise a répété les retards ou carrément les non-paiements de salaires et de taxes sur les salaires, amenant AWS — que Stability utilise pour le calcul nécessaire à l’entraînement de ses modèles — à menacer de révoquer l’accès de Stability à ses instances GPU.
Stability AI a récemment levé 25 millions de dollars via une note convertible (c’est-à-dire une dette convertible en actions), portant son total levé à plus de 125 millions de dollars. Mais elle n’a pas clôturé de nouveaux financements à une valorisation plus élevée ; la startup était dernièrement valorisée à 1 milliard de dollars. Stability aurait cherché à quadrupler cela dans les prochains mois, malgré des revenus obstinément faibles et un taux de combustion élevé.
Stability a subi un autre coup dur récemment avec le départ d’Ed Newton-Rex, qui avait été vice-président de l’audio dans la startup pendant un peu plus d’un an et a joué un rôle crucial dans le lancement de l’outil de génération de musique de Stability, Stable Audio. Dans une lettre publique, Newton-Rex a déclaré qu’il avait quitté Stability suite à un désaccord sur le droit d’auteur et la manière dont les données protégées par le droit d’auteur devraient — et ne devraient pas — être utilisées pour entraîner les modèles d’IA.
Réflexions finales
En tant qu’aficionado de l’IA, vous serez peut-être intéressé de savoir que Stability AI a récemment annoncé un nouveau modèle d’IA appelé Stable Video Diffusion. Ce modèle a été conçu pour générer des vidéos en animant des images existantes, et est l’un des rares modèles de génération de vidéos disponibles en open source.
Cependant, il est important de noter que le modèle est actuellement en phase de « avant-première de recherche » et n’est pas destiné à des applications réelles ou commerciales à ce stade. Les utilisateurs doivent accepter certaines conditions d’utilisation avant de pouvoir y accéder, qui détaillent les applications prévues du modèle, ainsi que les utilisations non prévues.
Malgré certaines limitations, telles que l’incapacité de générer des vidéos sans mouvement ou de panoramiques lents de la caméra, ou de rendre le texte lisible, le modèle peut générer des clips de haute qualité de quatre secondes et peut être adapté à des cas d’utilisation comme la génération de vues à 360 degrés d’objets.
Stable Video Diffusion se présente sous deux modèles – SVD et SVD-XT, tous deux ayant été formés sur un ensemble de données de millions de vidéos. Une fois le modèle affiné grâce aux retours d’expérience et aux mesures de sécurité, il a le potentiel de faire un impact significatif dans diverses industries.
Ce modèle n’est qu’un des nombreux modèles open source développés par Stability AI qui couvrent des modalités telles que l’image, le langage, l’audio, la 3D et le code. Cette gamme diversifiée de modèles témoigne de l’engagement de l’entreprise à amplifier l’intelligence humaine et à fournir des technologies de pointe au monde.









